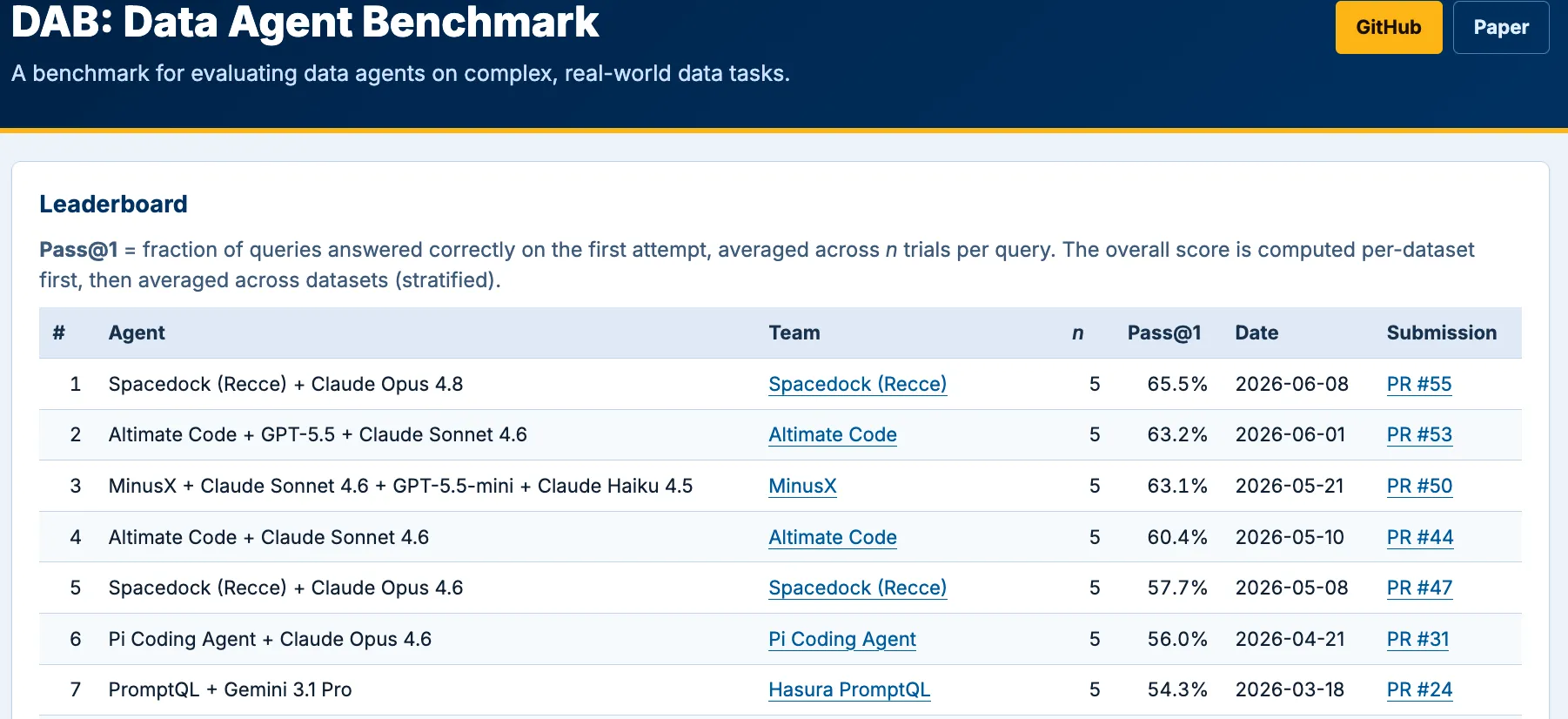
Spacedock is #1 on the Data Agent Benchmark (DAB) from UC Berkeley’s EPIC lab: 65.55%, more than 20 percentage points above the published baseline. DAB tests agents across dozens of queries spanning multiple database systems. What makes it hard is that the agent gets no map. It has to discover which tables exist, what the schema looks like, and how datasets join, all before it can answer anything.
The three-stage solver
We built Spacedock to run multi-stage agent workflows where each stage is a separate agent starting clean. The solver workflow we applied to each DAB query has three stages. First, a modeling agent maps the data landscape: it enumerates tables, samples values, identifies join keys, and writes a context document. Nothing else. Second, a fresh analysis agent reads that context document, answers the questions, and writes an answer file plus a reasoning trace. Third, a fresh verification agent re-derives each answer from the same context document, without seeing the analysis agent’s reasoning. It passes or rejects with numbered findings. Rejection routes back to analysis, at most three cycles.
The stage boundary is a context reset: each agent receives only the prior stage’s artifacts, with no access to prior reasoning. On the book review dataset, both single-agent configurations returned the 1980s for a question whose ground truth was the 2020s, including one explicitly told to adversarially review its own work. The fresh verification agent, working from only the answer file and reasoning trace, arrived at the 2020s independently. Adding prose instructions to a single agent moved the score by −0.008 across 12 datasets; switching to the multi-stage architecture moved it +0.070.
Discovered by running the loop
We also used Spacedock to run the experiments themselves. Each solver configuration moved through an outer experiment workflow: a quick smoke run to validate the setup before committing to full N=5 passes, then failure-mode analysis on the completed traces. That analysis generated the next round of hypotheses, each targeting a specific failure class. Force fewer joins on datasets where the modeling stage over-joined. SQL-first execution to stop the analysis agent from falling back to Python loops. Multi-stage scaffolding to isolate planning failures from implementation failures. Each hypothesis mutated the solver workflow by one step. The smoke gate meant bad ideas died in minutes, not hours. The loop made the flywheel run faster with each round. The architecture that reached number one is the union of what survived. It was not designed top-down. It was discovered by running the loop.
Workflow, not prose
Using multiple agents for independent adversarial review is not new. Systemizing and parameterizing it in a reproducible workflow has been hard. Spacedock uses a plain-text DSL to define and experiment with the topology, the stage handoffs, and the acceptance bar each agent checks against, all in a reviewable file. That makes failure-mode analysis tractable and the whole thing recursively improvable.
Result: Spacedock topped the full 12-dataset DAB leaderboard at 65.55% as of June 2026 (Claude Opus 4.8).
The full write-up is in the paper, “Workflow, Not Prose: A Multi-Agent Methodology for Data Agents,” presented at the SAO Workshop at ACM CAIS’26.
We will write more about razorback, a generic harbor-compatible benchmark harness workflow built on Spacedock.
In the meantime, try Spacedock with your existing Claude Code or Codex, and leave a GitHub star: github.com/spacedock-dev/spacedock.